![[Deep Dive] What is SDD?](/images/blogs/what-is-sdd/cover.webp)
The term SDD (Spec Driven Development) has been popping up everywhere this past year, and in Taiwan, it has become incredibly “hot” over the last six months.
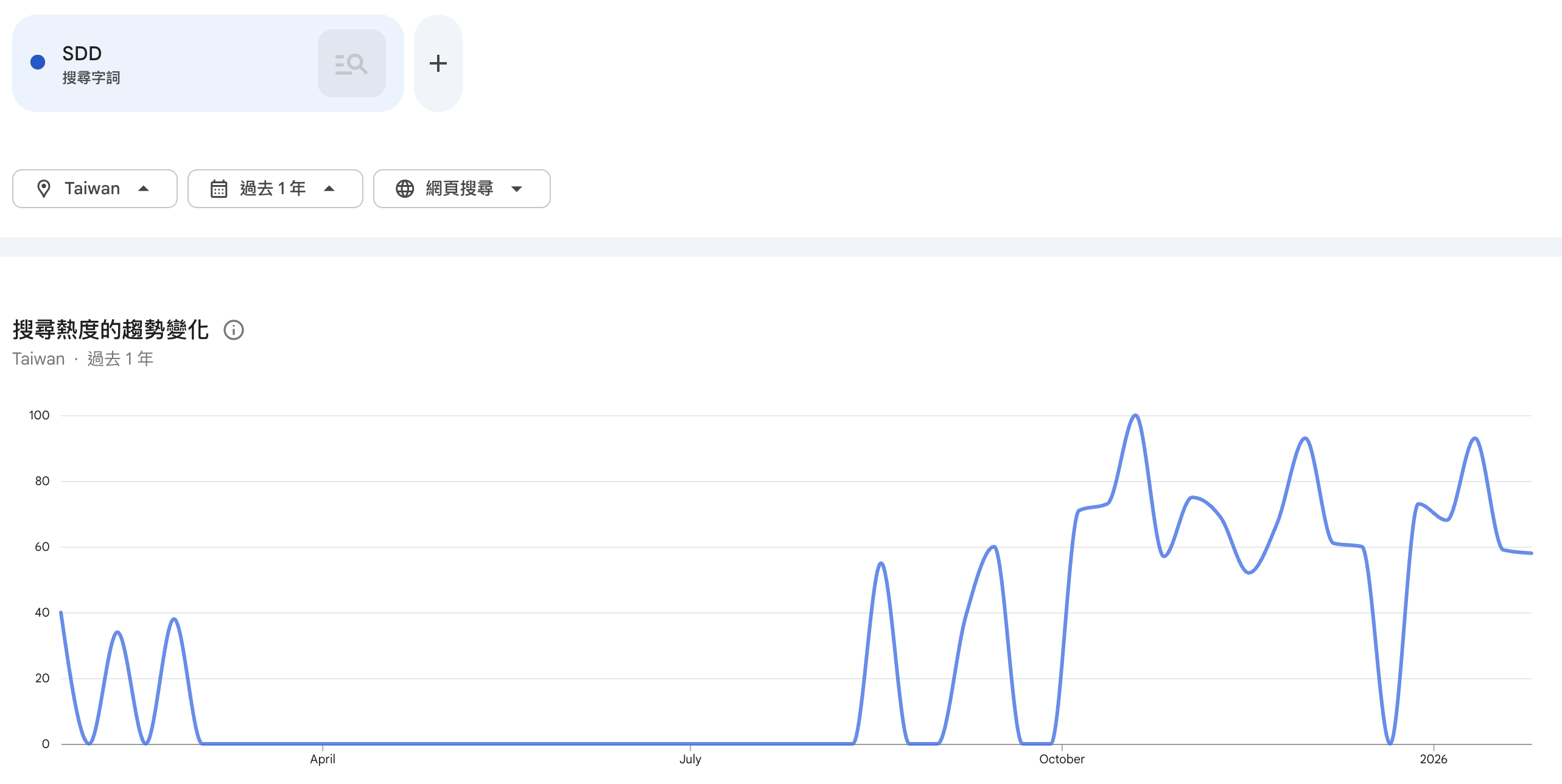
In a recent side project, while I was researching fully automated AI coding workflows, I decided to take a serious look at the core philosophy behind this buzzword.
The Traditional Software Development Workflow
As the old dev proverb goes: “If it works, don’t touch it.” Since traditional development processes have birthed some of the world’s greatest works, there must be a solid logic behind them.
In my view, a mature software product goes through several stages from idea to implementation:
- Idea converted into text
- Text converted into specs
- Specs converted into code
- Code converted into features
- Features converted into user experience
User experience then feeds back into new requirements, and the cycle repeats. Each cycle represents a product iteration.
This process is usually split between four roles: PM, SA, PG, and (QA) User.
PS: Large-scale teams usually have dedicated QA for quality testing, but for the sake of this discussion, let’s bundle them with the User.
Because a product is split across four different roles for development and feedback, “communication loss” has always been a nightmare. It often escalates into a “blood feud” between PMs and PGs. XD
In the past, we’ve tried various methodologies (e.g., Scrum, Agile, BDD, DDD) to reduce this communication friction and align everyone’s mental model.
The final output inevitably includes various specs:
Design & Planning Phase
- UI/UX Design Specs: Wireframes (low-fi) and Mockups (high-fi). Developers need these to confirm interface elements, spacing, colors, and component behavior.
- PRD: User Stories & Acceptance Criteria (AC). Sometimes broken down into granular stories with clear acceptance criteria as a basis for testing.
- WBS (Work Breakdown Structure): The project schedule, breaking down tasks into specific timelines (like Gantt Charts or Jira Backlogs).
Technical Research & Development Phase
- SA (System Analysis): Understanding business requirements and translating them into system functions. The SA is the bridge between the PRD and technical implementation.
- SD (System Design): Deeper than SA, focusing on specific module design and logic flowcharts.
- API Documentation: Usually written in Swagger or Postman, defining inputs, outputs, error codes, and formats.
- ER Model / Database Schema: Defining DB tables, field types, and relationships (ER Diagram).
- Flowchart / Sequence Diagram: Describing system interactions under complex logic.
Quality Assurance Phase
- Test Plan: Defining test scope, environment, strategy, and resource allocation.
- Test Case: Detailed records of “Input X, expect Output Y,” covering happy paths and corner cases.
- QA / Bug Report: A summary of test results, remaining bugs, and risk assessment.
Release & Operations Phase
- Release Notes: Documenting new features, fixed bugs, and known limitations.
- User Manual / Help Center: External tutorials for customers; internal FAQs for customer support.
- Maintenance Manual: Environment configs, troubleshooting flows, and emergency contact points.
A standard Software Development Life Cycle (SDLC) typically looks like this:
| Phase | Documents |
|---|---|
| Discovery | Market Research, PRD |
| Design | UI/UX Prototypes, SA Spec |
| Development | SD, API Doc, Database Schema |
| Testing | Test Cases, Test Report |
| Release | Release Notes, User Manual |
Now, let’s look at what SDD—which has surged in popularity thanks to “vibe coding”—actually does.
SDD (Spec Driven Development)
To be honest, when I first saw the term SDD, my first thought was: “Spec Driven Development? Isn’t that what we’ve always been doing? How do you even develop without specs?”
But skepticism aside, there’s a reason this methodology is blowing up. Let’s break it down.
Context: Vibe Coding
Over the past year, the barrier to entry for software engineering has been lowered significantly by “Vibe Coding.” As long as you can write a few prompts, AI can generate prototypes or scripts for simple needs.
But with that comes problems: exposed API keys, sensitive data leaks, insecure code, features built on shaky architectures, and a total lack of debugging skills. Things that used to be “fireable offenses” are now commonplace. Because the barrier to entry is gone.
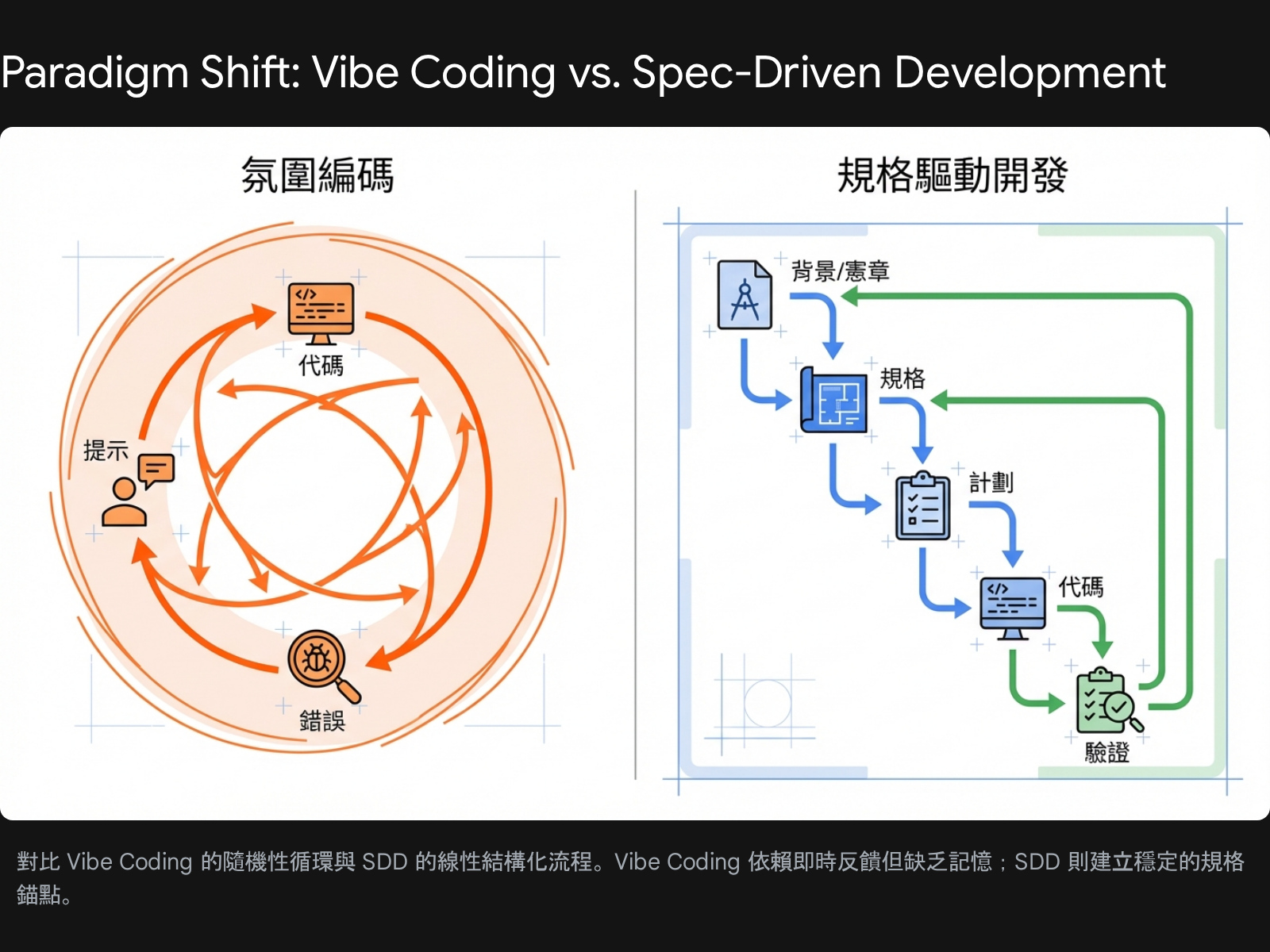
(The following is an excerpt from an AI response):
The core epiphany of SDD is recognizing that AI is essentially a probabilistic prediction engine, not a logical reasoning engine (at least in the GPT-4 era). Without strong external constraints, AI tends to wander randomly within a massive solution space, looking for the “most likely” path rather than the “most correct” one.
The emergence of SDD shifts the focus of software development from “writing implementation details” to “defining system boundaries.” In this mode, specs are no longer stale documents but “Executable Assets.” Developers have found that by maintaining high-definition spec files and forcing the AI to follow them, they can effectively “lock” the AI’s behavior, eliminating the risks brought by its randomness. This marks a fundamental paradigm shift from “Humans writing code” to “Humans writing specs, AI writing code.”
The Method: Clear and Detailed Spec Files (?)
Let’s look at the approach used by the GitHub Spec Kit.
It mainly revolves around these files:
- constitution.md: Your constitution, recording existing architectural patterns and constraints.
- spec.md: Feature specs considering existing infrastructure and integration points.
- plan.md: The plan showing how new features integrate into the existing architecture, rather than isolated implementations.
Finally, a tasks.md is generated to drive development.
After looking closely, I realized this still doesn’t completely avoid the randomness of code generation.
At its heart, this is still Prompt Engineering—trying to constrain LLM behavior. But you still can’t be 100% sure the code output will be consistent every time. You’re still playing a “gacha game,” just with better pull rates.
Looking at the different levels of SDD (Spec-first, Spec-anchored, Spec-as-source), even with today’s tech, we can’t truly achieve Spec-as-source yet—especially when spec.md and plan.md are just natural language Markdown files with huge gaps in implementation details. Most people are currently at the second stage: Spec-anchored.
However, the overall workflow is still positive. It genuinely solves the “vibe coding” mess by giving the code a reference spec and an iterative mechanism.
But if that’s the case, why not just use AI to collaborate on more robust documentation?
Since AI has decades of training data, it should already be an expert on what a PRD, SA Spec, SD, API Doc, DB Schema, and Flowchart look like, right?
Tweaking the SDD Approach
Since “Spec” doesn’t have a mandatory format, I think using traditional PRD and SA Specs as substitutes for constitution.md, spec.md, and plan.md is perfectly viable. Even better, I can define more detailed specifications within the SA spec (e.g., integration methods for external APIs).
As AI models start “pumping their stat points into reasoning,” I believe sufficiently detailed documentation remains the best choice.
For me, if I have a PRD and an SA Spec that are detailed enough, that’s plenty for most developers (and AIs) to generate code.
Ultimately, AI should learn to think like a human, rather than humans teaching AI how to think.
I think when we start designing sets of rules or fancy new terms just to make things easier for AI, we might be putting the cart before the horse.
At the end of the day, it all comes back to the traditional product cycle: Write spec -> Implement -> Feedback.
The biggest selling point of SDD right now is that where traditional development relied on a whole team, now it just takes one developer and an AI. Communication loss becomes zero.
Developers can use AI as a leverage tool to pry into domains they previously didn’t understand, leading to rich results.
So, looking back, does an SDD spec have to follow constitution.md, spec.md, and plan.md? Not necessarily.
If you implement it using terms you’re already familiar with and skills you’ve already learned, the results will be just as good.
Oh! I actually happen to have an SDD implementation detail of my own right here XD. Check it out if you’re interested: https://github.com/Tai-ch0802/arc-like-chrome-extension/blob/main/.github/i18n/en/README.md#-contributing
The effect I hope to achieve is transforming vague requirements into implementable code. When this process becomes an SOP, the barrier for the community to contribute drops. When contributing is as easy as ordering from a vending machine, it boosts the motivation to “turn ideas into reality.”
Just as the emergence of AI brought the creative wave of “vibe coding.”
Conclusion
I originally just wanted to understand the difference between SDD and traditional workflows (PRD + SA spec). I didn’t even plan on using SDD. But after looking into it, I realized that anyone who has worked in a SI (System Integrator) probably already understands these concepts.
It’s just that today’s context is driven by vibe coding, which gives these existing layers of knowledge a shiny new name.
Spec-first, verifiable requirements, Spec-anchored, and version-controlled thinking—all these existed long before SDD. SDD simply links these concepts together within a single repo.
If there’s one major difference, it’s that SDD has only one participant. So there are no “consensus gaps” to deal with.
In conclusion, I suspect the “SDD” hype might cool off in a year or two. AI will get stronger—strong enough to produce high-quality, stable code even from vague ideas. Not to mention that all the intermediate specs will be auto-generated by AI, with you only needing to check in occasionally.
When products can be summoned directly from vague concepts, maybe Spec-as-Code won’t even be cool enough anymore.
The future belongs to Idea-as-Code. All you’ll need to do is make a wish.